Please enable JavaScript.
Coggle requires JavaScript to display documents.
Crowd Counting (dataset (:four:Shanghaitech dataset (Part_A (have a large…
Crowd Counting
:one:people counting
:link:
reference
related work
:one:监控视频中人群计数算法
steps
:two:特征提取
分割得到的前景
=> 底层特征
常用的特征
人群面积和周长、边缘信息、纹理特征、闵可夫斯基维度等
:three:人数回归
底层特征 => 人数
回归方法
线性回归、分段线性回归、脊回归、高斯过程回归等
:one:前景分割
algorithm
光流法、混合动态纹理、小波分析 、背景差分等
:two:单幅图像人群计数算法
人群分割比视频更困难
没有运动信息
整张图像 / 图像分块
=> 提取特征
=> 人群数量
图像分块
离散化特视效果
:three:基于深度学习的人群计数算法
CVPR2015的Cross-scene Crowd Counting via Deep Convolutional Neural Networks
:apple:CVPR2016的Single-Image Crowd Counting via Multi-Column Convolutional Neural Network
:green_apple:challenges
:one:foreground segmentation
:explode:If we want to do foreground segmentation, we must provide information about scene geometry or motion / viewpoint, otherwise it will be very difficult.
:check:viewpoint
:red_cross:
In this paper, the viewpoint can be arbitrary => cannot do foreground segmentation
:question:What is the foreground segmentation? Why does it have a connection with viewpoints?
:two:density, distribution & occlusions
:red_cross:traditional detection-based methods
:question:Why traditional methods fail in such images or situations?
:three:scale of the people
:question:Why it is difficult to handcraft features for all different scales if we do not have tracked features?
:question:Why is it a problem?
:two:MCNN
:one:methods of counting people
:one:direct
:bread:output the number of people directly
:two:indirect :coffee:
:bread:image => density map (
#people / m^2
) => (using integral)
#people
:pineapple:reasons of recommendation
:one:preserve more information
:question:Don't the interim outputs of the CNN using the first method contain much information, either?
密度图保留更多的信息。与人群的总数相比,密度图给出了在给定图像中人群的空间分布,这样的分布信息在许多应用中是有用的。例如,如果一个小区域的密度比其他区域的密度高得多,它可能表明一些异常发生在那里。
:two:adaptive + heads of different sizes
更适合于有透视效果显着变化的任意输入。所以这些滤波器具有更多的语义,提高了人群计数的准确性
:question:Why?
:explode:the learned filters are more adapted to heads of different sizes
:two:Density map via geometry-adaptive kernels
:checkered_flag:original image => density map
an image with N heads labeled can
be represented as a function
:question:it is stated that
xi
is used to represent the pixel position of a head, but how many points does
xi
represent? Since we know that a head always occupy with many points
δ(x−xi)表示图像中人头位置的冲击函
N为图像中的人头总数,
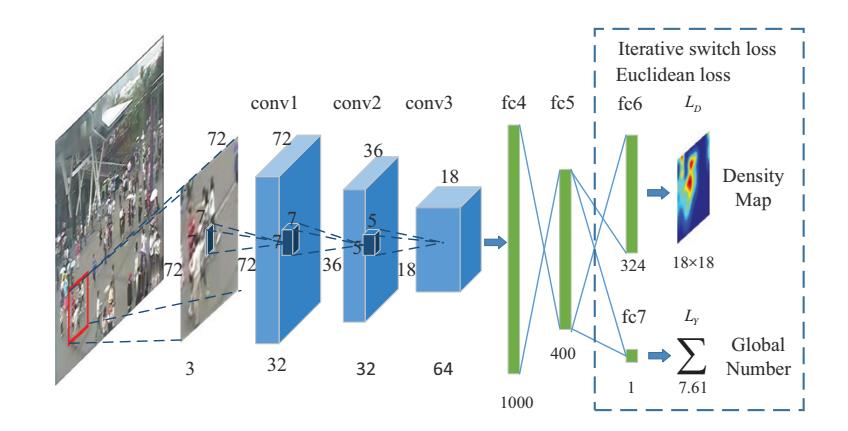
:three:Multi-column CNN for density map estimation
:question:How to use linear weighting function to obtain the density map by 1*1 kernel map from several feature maps?
a denstiy map is 4d as well, so it’s okay to use cnn
优化欧式函数
输出的密度图 => 标准的密度图
loss function
:question:What’s the meaning of double 2
:question:the shape of the Fi?
:four:Optimization of MCNN
initialization
第四层当作最后输出的密度图
分别训练网络的每一层
将每一层参数用了初始化网络并微调
:apple:Why
the training dataset is limited
:question:why? Is it because that it is difficult to obtain them? Or there is no ready-made dataset
深度神经网络存在梯度弥散问题
:question:why
:five:Transfer learning setting
MCNN的一个优势在于能学习到不同大小人头对应的密度图。因此,如果该模型用一个包含各种大小人头的大数据集来训练,则该模型可以很容易地适应(或迁移)到另一个人头大小是一些特定的尺寸的数据集。如果目标域只包含少量的训练样本,可以简单地将MCNN的每一列前几层固定,只有微调最后的少量卷积层。这样固定前几层使在源域中学习的知识可以被保留,微调后几层很大程度上降低了模型适应目标域的计算复杂度。
a graph with different sizes of heads => graph with fixed size of heads
:coffee:fine-tune the last few layers
:one:preserve(first several layers) & adapt(last few layers)
:two:reduce the computational complexity
:one:Introduction
:one:contributions
:one:multi-column architecture
:checkered_flag:三列对应不同大小的感应野(大中小),使每个列卷积神经网络的功能对由于透视或不同的图像分辨率造成的人/头大小变化是自适应的(因此,整体网络是强大的)
:question:什么是列?
:two:
1*1
filter size
用一个1*1滤波器的卷积层代替了完全连接的层,因此模型的输入图像可以是任意大小的,避免了失真。网络的直接输出是一个人群密度估计图,从中可以得到的整体计数
:question:
1*1
滤波器怎么代替fc?为什么图像可以是任意大小?Why this can avoid distortion?
:three:new dataset
收集了一个新的数据集用于人群计数方法的评价。比现有的数据集包含更复杂的情况,能更好地测试方法性能,1198张图,330,165精确标定的人头。数据集分A和B两个部分,A是从互联网上随机找的图,B是上海的闹市截取图,如图5所示为A、B部分图
:three:
dataset
:four:Shanghaitech dataset
Part_A
have a large number of people
randomly crawled from the Internet
Part_B
taken from busy streets of metropolitan areas in Shanghai
:fire:No viewpoints
:one:UCF_CC_50 dataset
the number of images is low
not suitable to deep learning
50 images
:two:UCSD dataset
:three:WorldExpo
:link:
all methods to crowd counting